Discusses how to use different floating point precisions available in the GPU, and how to take advantage of smaller representations to improve runtime performance.
By Juan Adarve |
Jupyter notebook:
A Jupyter notebook with the code in this article is available in Google Colab. Check it out!
GPU devices support several floating point number precisions, where precision refers to the number of bits used for representing a given number. Typical representations are:
FP16: or half precision. Numbers are represented in 16 bits.
FP32: or single precision. It uses 32 bits for representing a number.
FP64: or doble precision. 64 bits are used for represeting a number.
FP64 is used when numerical precision is required, while FP16 is suitable for fast, less exact calculations, and FP32 sits in the middle. The IEEE 754 standard defines the specification of floating point numbers used in modern computers. It defines the rules for interpreting the bit fields that form a number, as well as the arithmetic rules to process them.
The Vulkan API offers support for the three floating point precisions. However, not all GPUs support every format. The Vulkan GPU Info page is great tool to check support for a given feature.
Improvements in runtime performance
Smaller bit representation of floating point numbers have an advantage in terms of runtime performance. Consider the case of a RGBA image. If the image channel type is ll.ChannelType.Float16, the four pixel values will fit in 8 bytes, compared to the 16 bytes needed if ll.ChannelType.Float32 was used. This reduction in memory footprint increases the pixel transfer rate from memory to the compute device.
To illustrate this, let’s consider the optical flow filter node. The code below configures the flowfilter algorithm both with ll.FloatPrecision.FP16 and ll.FloatPrecision.FP32, it runs each node for N = 10000 iterations and collects its runtime using the duration probe.
importlluviaasllimportnumpyasnpsession = ll.createSession()
memory = session.createMemory([ll.MemoryPropertyFlagBits.DeviceLocal])
host_rgba = np.zeros((1016, 544, 4), dtype=np.uint8)
in_rgba = memory.createImageViewFromHost(host_rgba)
RGBA2Gray = session.createComputeNode('lluvia/color/RGBA2Gray')
RGBA2Gray.bind('in_rgba', in_rgba)
RGBA2Gray.init()
N =10000runtimeMilliseconds = {
ll.FloatPrecision.FP16 : np.zeros((N), dtype=np.float32),
ll.FloatPrecision.FP32 : np.zeros((N), dtype=np.float32)
}
for precision in [ll.FloatPrecision.FP32, ll.FloatPrecision.FP16]:
flowFilter = session.createContainerNode('lluvia/opticalflow/flowfilter/FlowFilter')
flowFilter.setParameter('levels', ll.Parameter(2))
flowFilter.setParameter('max_flow', ll.Parameter(2))
flowFilter.setParameter('smooth_iterations', ll.Parameter(2))
flowFilter.setParameter('gamma', ll.Parameter(0.0005))
flowFilter.setParameter('gamma_low', ll.Parameter(0.0005))
# use selected floating point precision flowFilter.setParameter('float_precision', ll.Parameter(precision.value))
flowFilter.bind('in_gray', RGBA2Gray.getPort('out_gray'))
flowFilter.init()
duration = session.createDuration()
cmdBuffer = session.createCommandBuffer()
cmdBuffer.begin()
cmdBuffer.run(RGBA2Gray)
cmdBuffer.memoryBarrier()
# probe the runtime of the flowfilter node cmdBuffer.durationStart(duration)
cmdBuffer.run(flowFilter)
cmdBuffer.memoryBarrier()
cmdBuffer.durationEnd(duration)
cmdBuffer.end()
# run the command buffer N times and collect the runtime of the flow algorithmfor n inrange(N):
session.run(cmdBuffer)
runtimeMilliseconds[precision][n] = duration.nanoseconds /1e6
Here, the ll.FloatPrecision.FP16, ll.FloatPrecision.FP32 are new enum values for representing 16-bit and 32-bit floating point precision, respectively. The line flowFilter.setParameter('float_precision', ll.Parameter(precision.value)) configures the node with the given precision. Internally, the float_precision is used to instantiate any floating point image with the requested precision.
Note:
By convention, any node that allows selecting floating point precision will define the float_precision parameter and will expect one of the ll.FloatPrecision enum values.
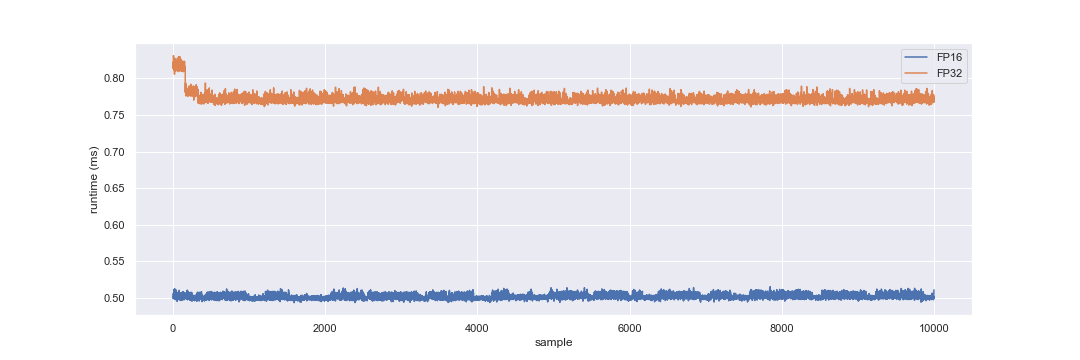
The figure below shows the collected runtime for both floating point precisions. The median runtime for FP16 is 0.501ms, while for FP32 is 0.770ms. That is, the FP16 algorithm improves the runtime by 35% compared to FP32.
Optical flow filter runtime using FP16 and FP32 floating point precision. Results collected on a Nvidia GTX-1080 (driver 460.91.03) running Ubuntu 20.04.
Modifications to GLSL shader code
In terms of GLSL shader code, there are no changes to support FP16 or FP32 images. However, it is important to understand the underlying functioning. For instance, consider the GLSL implementation of the RGBA2HSVA compute node. Notice that the out_hsva port is bound to the shader as a rgba32f image:
Images compatible with the rgba32f image format can be bound as output. The shader image load store extension defines the compatibility rules to be able to bind images to shaders. For this case in particular, it is possible to bind either a rgba16f or rgba32f images to the output. The shader will execute all arithmetic operations using 32-bit floating point precision. When storing an image texel using imageStore(out_hsva, coords, HSVA), the shader will reinterpret the vec4 HSVA either as a 16 or 32-bit floating vector, according to the image bound to out_hsva.
In terms of Lua code to build the node, these are the considerations to support different precisions:
Define the float_precision parameter with default value to ll.FloatPrecision.FP32.
Allocate the node objects according to the selected precision.
In the code below, line local outImageChannelType = ll.floatPrecisionToImageChannelType(float_precision) transforms the recevied ll.FloatPrecision value to the corresponding ll.ChannelType. Then, out_hsva is created and bound to the node.
local builder = ll.class(ll.ComputeNodeBuilder)
builder.name ='lluvia/color/RGBA2HSVA'functionbuilder.newDescriptor()
local desc = ll.ComputeNodeDescriptor.new()
desc:init(builder.name, ll.ComputeDimension.D2)
-- define the float_precision parameter with default value desc:setParameter('float_precision', ll.FloatPrecision.FP32)
local in_rgba = ll.PortDescriptor.new(0, 'in_rgba', ll.PortDirection.In, ll.PortType.ImageView)
in_rgba:checkImageChannelCountIs(ll.ChannelCount.C4)
in_rgba:checkImageChannelTypeIs(ll.ChannelType.Uint8)
desc:addPort(in_rgba)
desc:addPort(ll.PortDescriptor.new(1, 'out_hsva', ll.PortDirection.Out, ll.PortType.ImageView))
return desc
endfunctionbuilder.onNodeInit(node)
local in_rgba = node:getPort('in_rgba')
-- receive the selected float_precisionlocal float_precision = node:getParameter('float_precision')
-- transform float precision to a suitable image channel typelocal outImageChannelType = ll.floatPrecisionToImageChannelType(float_precision)
--------------------------------------------------------- allocate out_hsva-------------------------------------------------------local imgDesc = ll.ImageDescriptor.new()
imgDesc.width = in_rgba.width
imgDesc.height = in_rgba.height
imgDesc.depth = in_rgba.depth
imgDesc.channelCount = ll.ChannelCount.C4
imgDesc.channelType = outImageChannelType
local imgViewDesc = ll.ImageViewDescriptor.new()
imgViewDesc.filterMode = ll.ImageFilterMode.Nearest
imgViewDesc.normalizedCoordinates =false imgViewDesc.isSampled =false imgViewDesc:setAddressMode(ll.ImageAddressMode.Repeat)
-- ll::Memory where out_hsva will be allocatedlocal memory = in_rgba.memory
local out_hsva = memory:createImageView(imgDesc, imgViewDesc)
-- need to change image layout before binding out_hsva:changeImageLayout(ll.ImageLayout.General)
node:bind('out_hsva', out_hsva)
node:configureGridShape(ll.vec3ui.new(out_hsva.width, out_hsva.height, 1))
end-- register builder in the systemll.registerNodeBuilder(builder)
Discussion
There are several floating point precisions available to use in compute shaders: FP16, FP132, and FP64, are the ones more commonly available in commodity GPU hardware. The ability to control the underlying floating point precision used in compute pipelines can improve runtime performance, as the transfer rate of data from and to memory can increase. The choice of a given precision must be made carefully, as it might affect the accuracy of the algorithm.